新聞/文章 August 13, 2025
【新知】Google 發佈可讓 AI 訓練所需資料量減少一萬倍的優化方法
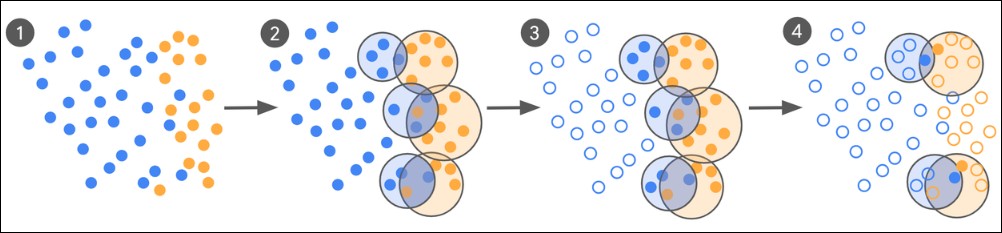
這一流程以人類專業知識為核心,結合模型自身的初步分類能力,採取「先粗後精」的閉環式優化方式:
-
少樣本啟動 以零樣本或少樣本(few-shot)方式,先讓模型根據既有標籤(例如「安全廣告」與「不安全廣告」)進行初步分類。
-
識別邊界樣本 模型在大多數案例中能做出明確判斷,但會出現一部分「邊界樣本」,即模型判斷模糊或可能出錯的案例。
-
專家標註邊界樣本 這些邊界樣本被送交人類專家進行精確標註。由於標註範圍僅限於高不確定性案例,所需的人工標註量遠低於全量數據。
-
模型再訓練與循環迭代 將專家標註結果重新用於模型微調,並重複上述流程,直到性能提升趨於穩定。
這種方法的關鍵在於將專家資源集中投入在最具爭議性、最能影響模型判斷的案例,避免在大量容易分類的樣本上浪費人力。
Sharing is sexy
Latest article
- 【CL-12】Thinking about the Care Group Curation System
- 【CF-42】(Updated: May 18) ED相關理論及社會狀況 (多個AI模型)
- 【CL-11】From MOC to an Unified Information System (System Design / PARA Integration / Books into Skills / AI Librarian)
- 【CL-10】Setting Up a Board for ClaudioFlute in Super Productivity
- 【CF-39】Using VST Live Pro for Show Production
